3D-Daten durch Stereo Vision
1. Abstrakt
Dieses Whitepaper gibt einen Überblick über die wichtigsten Verarbeitungsschritte für die Tiefenwahrnehmung mit einer Stereokamera. Nach der Beschreibung der allgemeinen Techniken gehen wir auf die Besonderheiten von Ensenso Stereokameras ein, um das klassische Stereo Vision Verfahren zu verbessern.
2. Das Prinzip des räumlichen Sehens
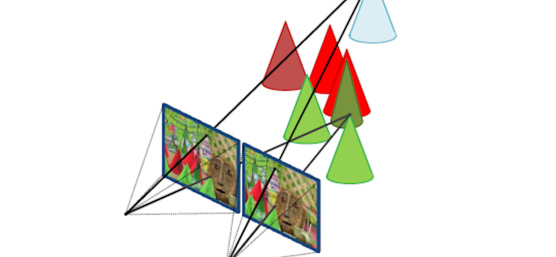
Die Tiefenwahrnehmung beim Stereosehen basiert auf dem Triangulationsprinzip. Wir verwenden zwei Kameras mit Projektionsoptik und ordnen sie nebeneinander an, sodass sich ihre Sichtfelder in der gewünschten Objektentfernung überlappen. Indem wir mit jeder Kamera ein Bild aufnehmen, erfassen wir die Szene aus zwei verschiedenen Blickwinkeln. Dieser Aufbau ist in Abbildung 1 dargestellt.

Für jeden in beiden Bildern sichtbaren Oberflächenpunkt gibt es zwei Strahlen im 3D-Raum, die den Oberflächenpunkt mit dem Projektionszentrum jeder Kamera verbinden. Um die 3D-Position der aufgenommenen Szene zu erhalten, müssen wir hauptsächlich zwei Aufgaben erfüllen: Erstens müssen wir feststellen, wo sich jeder Oberflächenpunkt, der im linken Bild sichtbar ist, im rechten Bild befindet. Und zweitens muss die genaue Kamerageometrie bekannt sein, um den Strahlenschnittpunkt für die zugehörigen Pixel der linken und rechten Kamera zu berechnen. Da wir davon ausgehen, dass die Kameras fest miteinander verbunden sind, wird die Geometrie nur einmal während des Kalibrierungsprozesses berechnet.
3. Kamera-Kalibrierung
Die Geometrie des Zwei-Kamera-Systems wird im Stereokalibrierungsprozess berechnet. Zunächst benötigen wir ein Kalibrierobjekt. In der Regel ist dies eine ebene Kalibrierplatte mit einem Schachbrettmuster oder Punktmuster bekannter Größe. Dann nehmen wir synchrone Bildpaare auf, wobei das Muster in beiden Kameras unterschiedliche Positionen, Orientierungen und Abstände aufweist. Die Pixelpositionen der Punkte des Musters in jedem Bildpaar und ihre bekannten Positionen auf der Kalibrierplatte können verwendet verwenden, um sowohl die 3D-Posen aller beobachteten Muster, als auch ein genaues Modell der Stereokamera zu berechnen. Das Modell besteht aus den sogenannten intrinsischen Parametern jeder Kamera wie Brennweite und Linsenverzerrung und den extrinsischen Parametern, d. h. der Drehung und Verschiebung in drei Dimensionen zwischen der linken und rechten Kamera. Mit diesen Kalibrierdaten können wir entsprechende Punkte, die in beiden Bildern identifiziert wurden, triangulieren und ihre metrischen 3D-Koordinaten in Bezug auf die Kamera wiederherstellen.

4. Verarbeitungsschritte für die Tiefenberechnung
Die folgenden drei Abschnitte beschreiben die Verarbeitungsschritte, die für die Berechnung der 3D-Position für jedes Pixel eines Bildpaars erforderlich sind. Diese Schritte müssen in Echtzeit für jedes aufgenommene Stereobild durchgeführt werden, um eine 3D-Punktwolke oder eine Oberfläche der Szene zu erhalten.
4.1 Rektifizierung
Um die abgebildeten Punkte zu triangulieren, müssen wir die entsprechenden Bildteile im linken und rechten Bild identifizieren. Wenn wir einen kleinen Bildausschnitt aus dem linken Bild betrachten, könnten wir einfach das gesamte rechte Bild nach einer ausreichend guten Übereinstimmung durchsuchen. Dies wäre zu zeitaufwändig, um in Echtzeit zu arbeiten. Betrachten Sie das Beispielbildpaar in Abbildung 3, bei dem die Kegelspitze oben im linken Bild sichtbar ist. Intuitiv scheint es nicht notwendig zu sein, die Spitze des Konus in der unteren Hälfte des rechten Bildes zu suchen, wenn die Kameras nebeneinander montiert sind. Tatsächlich erlaubt die Geometrie der beiden Projektionskameras die Suche auf eine eindimensionale Linie im rechten Bild, die sogenannte Epipolarlinie, zu beschränken.

Abbildung 2 (oben) zeigt ein Stereobildpaar mit einigen handmarkierten Punktkorrespondenzen und deren Epipolarlinien. In den rohen Kamerabildern sind die Epipolarlinien aufgrund der durch die Kameraoptik verursachten Verzerrungen gekrümmt. Die Suche nach Korrespondenzen entlang dieser gekrümmten Linien wird ziemlich langsam und kompliziert sein, aber wir können die Bildverzerrungen durch die umgekehrte Anwendung der während des Kalibrierprozesses gelernten Verzerrungen entfernen. Die resultierenden unverzerrten Bilder haben gerade Epipolarlinien, die in Abbildung 2 (Mitte) dargestellt sind.
Obwohl sie gerade sind, haben die Epipolarlinien in verschiedenen Teilen jedes Bildes unterschiedliche Orientierungen. Dies wird dadurch verursacht, dass die Bildebenen (d. h. die Sensoren aus Kameras) weder perfekt koplanar noch identisch ausgerichtet sind. Um die Korrespondenzsuche weiter zu beschleunigen, können wir die Kamerageometrie aus der Kalibrierung verwenden und eine zusätzliche perspektivische Transformation auf die Bilder anwenden, sodass die Epipolarlinien mit den Bildscanlinien ausgerichtet werden. Dieser Schritt wird als Entzerrung bezeichnet. Die Suche nach der Spitze des weißen Kegels kann nun durchgeführt werden, indem man einfach die gleiche Scanlinie im richtigen Bild betrachtet und die am besten passende Position findet. Die gesamte weitere Verarbeitung findet nur in den entzerrten Bildern statt, die resultierenden Bilder sind in Abbildung 2 (unten) dargestellt.
4.2 Stereo Matching
Für jedes Pixel im linken Bild können wir nun nach dem Pixel auf derselben Scanlinie im rechten Bild suchen, das denselben Objektpunkt erfasst hat. Da ein einzelner Pixelwert in der Regel nicht ausreicht, um das entsprechende Pixel zuverlässig zu finden, versucht man in der Regel, kleine Fenster (z.B. 7x7 Pixel) um jedes Pixel herum mit allen möglichen Fenstern im rechten Bild in der gleichen Zeile abzugleichen. Als weitere Einschränkung müssen wir nicht die gesamte Zeile durchsuchen, sondern nur eine begrenzte Anzahl von Pixeln links von der x-Koordinate des linken Bildpixels, was dem leicht schielenden Blick entspricht, der zum Fokussieren in der Nähe von Objekten erforderlich ist. Dies beschleunigt die Anpassung und schränkt den Tiefenbereich ein, in dem Punkte trianguliert werden können. Wenn eine ausreichend gute und eindeutige Übereinstimmung gefunden wurde, ordnen wir das linke Bildpixel dem entsprechenden rechten Bildpixel zu. Die Assoziation wird in der Disparitätskarte in Form eines Versatzes zwischen den Pixel-X-Positionen gespeichert (siehe Abbildung 4).

Diese Anpassungstechnik wird als lokales Stereo-Matching bezeichnet, da sie nur lokale Informationen um jedes Pixel herum verwendet. Natürlich können wir einen Bereich zwischen dem linken und rechten Bild nur dann abgleichen, wenn er sich von anderen Bildteilen auf der gleichen Abtastlinie ausreichend unterscheidet. Daher wird der lokale Stereoabgleich in Regionen mit schlechter oder sich wiederholender Textur fehlschlagen. Andere Methoden, die als globales Stereo-Matching bezeichnet werden, können sich benachbarte Informationen zunutze machen. Sie betrachten nicht nur jedes Pixel (oder jeden Bildpunkt) einzeln, um nach einem passenden Partner zu suchen, sondern versuchen stattdessen, eine Zuordnung für alle linken und rechten Bildpunkte auf einmal zu finden. Diese globale Zuordnung berücksichtigt auch, dass die Oberflächen meist glatt sind und daher benachbarte Pixel oft ähnliche Tiefen haben. Globale Methoden sind komplexer und benötigen mehr Verarbeitungsleistung als der lokale Ansatz, aber sie benötigen weniger Textur auf den Oberflächen und liefern genauere Ergebnisse, insbesondere an den Objektgrenzen.
4.3 Reprojektion
Unabhängig von der verwendeten Matching-Technik ist das Ergebnis immer eine Zuordnung zwischen den Pixeln des linken und rechten Bildes, die in der Disparitätskarte gespeichert wird. Die Werte in der Disparitätskarte kodieren den Versatz in Pixeln, wobei die entsprechende Stelle im rechten Bild gefunden wurde. Abbildung 4 veranschaulicht den Disparitätsbegriff. Wir können dann wiederum die während der Kalibrierung erhaltene Kamerageometrie verwenden, um die pixelbasierten Disparitätswerte in tatsächliche metrische X-, Y- und Z-Koordinaten für jedes Pixel umzuwandeln. Diese Umrechnung wird als Reprojektion bezeichnet. Wir können einfach die beiden Strahlen jedes zugehörigen linken und rechten Bildpixels schneiden, wie in Abbildung 1 dargestellt. Die resultierenden XYZ-Daten werden als Punktwolke bezeichnet. Sie wird oft als Dreikanalbild gespeichert, um auch die benachbarten Informationen des Punktes aus dem Pixelraster des Bildes zu erhalten. Eine Visualisierung der Punktwolke ist in Abbildung 5 dargestellt.

5. Anwendungsspezifische Verarbeitung
Die drei beschriebenen Verarbeitungsschritte müssen auf dem Stereo-Image-Paar durchgeführt werden, um die vollständige 3D-Punktwolke der Szene zu erhalten. Die Punktwolke muss dann weiter verarbeitet werden, um eine spezifische Anwendung zu realisieren. Sie kann verwendet werden, um die Oberfläche der Szene mit einem bekannten Objekt abzugleichen, entweder aus einer früheren Punktwolke oder einem CAD-Modell gelernt. Wenn das Teil eindeutig in der erfassten Szenenoberfläche lokalisiert werden kann, kann die vollständige Position und Drehung des Objektes berechnet werden und es könnte z.B. von einem Roboter aufgenommen werden.
6. Ensenso Stereo Kameras
Wie bereits erwähnt, benötigen alle Stereo-Matching-Techniken texturierte Objekte, um die Entsprechungen zwischen dem linken und rechten Bild zuverlässig zu bestimmen. Da die Wahrnehmung von Texturen direkt von Lichtverhältnissen und den Oberflächenbeschaffenheiten der Objekte in der Szene abhängig ist, haben wenig texturierte bzw. spiegelnde Oberflächen direkte Auswirkungen auf die Qualität der resultierenden 3D-Punktewolke. Mit speziellen Techniken verbessern Ensenso Kameras das klassische Stereo Vision Verfahren, wodurch neben einer höheren Qualität der Tiefeninformation auch präzisere Messergebnisse erzielt werden.
Pattern-Projektor
Ensenso Stereokameras verwenden daher eine zusätzliche Texturprojektionseinheit. Während der Bildaufnahme ergänzt dieser Projektor die objekteigene Textur mit einem stark strukturierten Muster, um Mehrdeutigkeiten im Stereo-Matching-Schritt zu eliminieren. Dies gewährleistet eine dichte 3D-Punktwolke auch auf einfarbigen oder mehrdeutig strukturierten Oberflächen. Der Projektor und die Kameras werden außerdem durch ein Hardware-Triggersignal synchronisiert, um bei der Erfassung bewegter Objekte konsistente Bildpaare zu gewährleisten.
FlexView
Mit einer verschleißarmen Piezo-Mechanik kann die Position der Pattern-Maske im Lichtstrahl zusätzlich linear in sehr kleinen Schritten verschoben werden. Folglich verschiebt sich die projizierte Textur auf der Objektoberfläche der Szenenobjekte ebenfalls und erzeugt damit zusätzliche, variierende Informationen auf glänzenden, dunklen oder volumenstreuenden Oberflächen. Bei statischen Szenen können durch diese FlexView Technik mehrere Bildpaare mit unterschiedlichen Texturen aufgenommen werden, was in einer viel höheren Anzahl von Bildpunkten resultiert. Die größere Auflösung ermöglicht die Berechnung wesentlich detaillierterer Disparitätsbilder und Punktwolken, was sich ebenfalls in einer höheren Robustheit der 3D-Daten auf schwierigen Oberflächen widerspiegelt.
NxLib Stereo-Verarbeitungsbibliothek
Die NxLib-Bibliothek bildet die Schnittstelle zu den Kameras und implementiert die gesamte Stereoverarbeitungs-Pipeline, einschließlich der Kalibrierung. Sie kombiniert die Texturprojektion mit einer globalen Anpassungstechnik und liefert dichte, qualitativ hochwertige Punktwolken. Der streng parallelisierte globale Anpassungsalgorithmus kann alle Prozessorkerne nutzen, um eine Echtzeitleistung zu erzielen.

Dipl.-Ing. Heiko Seitz ist seit 2001 bei IDS tätig. Nach Jahren als Entwickler im Bereich Kamerasoftware unterstützt er heute als Product Marketing Manager die technologische Kommunikation bei IDS. Mit seiner Erfahrung schlägt er die Brücke zwischen komplexer Technik und praxisnaher Wissensvermittlung – etwa in Fachbeiträgen, Webinaren oder Vorträgen.
Vision Channel
Videos und Live Sessions rund um Machine Vision.
Ihr Projekt
Wie können wir Sie in Ihrem Projekt unterstützen? Gemeinsam finden wir die passende Lösung für Sie!
Newsletter
Bleiben Sie auf dem neuesten Stand und abonnieren Sie unseren Newsletter.